


L’article en quelques mots 📝
Mini résumé avec des infos maxi pour MiniMax-M1
👉 TL;DR : Avec MiniMax-M1, la Chine accélère dans la course mondiale à l’IA générative. Soutenue par Alibaba et Tencent, la startup MiniMax dévoile un LLM aux performances comparables aux leaders américains (GPT, Claude, Gemini), tout en misant sur l’open source et l’efficacité énergétique. Doté d’un contexte d’un million de tokens, M1 combine recherche de pointe (MoE, lightning attention, CISPO) et accessibilité, à un coût divisé par 4. Cette percée technologique confirme la montée en puissance des acteurs chinois dans l’intelligence artificielle, notamment dans les usages industriels, éducatifs et linguistiques à grande échelle.
Depuis sa création en décembre 2021 à Shanghai par Yan Junjie, Yang Bin et Zhou Yucong, MiniMax s’est imposé comme l’une des « AI Tigers » chinoises, avec de solides soutiens financiers (Alibaba, Tencent ou encore Hillhouse) et une stratégie résolument tournée vers l’open‑source. Déjà à l’origine de modèles comme Abab 6.5, Text‑01, VL‑01, de son offre multimodale Hailuo 02 et Speech 02, l’entreprise dispose d’un solide héritage en technologies d’IA multimodales et d’une R&D riche et variée.
Ce 17 juin 2025, celle-ci a dévoilé MiniMax‑M1, un modèle de langage (LLM) qui repousserait encore davantage les limites de l’IA générative : 1 million de tokens en contexte d’entrée, architecture hybride MoE + « lightning attention », formation ultra‑efficiente… LabSense vous explique dans cet article ce qui pourrait bien marquer une nouvelle ère pour l’IA à grand contexte.
À lire aussi

DeepSeek, Qwen2.5-Max, Janus-Pro : l’essor des IA chinoises
« La Chine poursuit son ascension fulgurante dans le domaine de l’intelligence artificielle (IA), jusqu’à remettre en question la suprématie des entreprises américaines telles que OpenAI, Google et Microsoft… » >> Lire la suite

Manus AI : L’agent intelligent autonome chinois ébahit et interroge
« L’intelligence artificielle connaît une accélération sans précédent, et la Chine se positionne en acteur majeur de cette révolution. Après l’impact de DeepSeek, un modèle IA plus économique et ouvert que ses homologues occidentaux, … » >> Lire la suite
📌 Qu’est‑ce que MiniMax‑M1 ?
Cette nouvelle version repose sur une architecture hybride associant MoE et lightning attention, combinée à une formation via RL optimisée. Véritable prouesse technique, l’IA chinoise MiniMax offre des innovations notables mais suscite aussi des interrogations sur son usage réel.
Il est principalement conçu pour du texte, mais l’architecture est multimodale, ce qui laisse entrevoir une extension future vers images ou vidéos via des composants comme Hailuo.
Caractéristiques techniques
Licence véritablement open-source
Publié sous licence Apache‑2.0, M1 est le premier modèle chinois à offrir un poids ouvert (open-weight) et une grande liberté d’utilisation
Architecture hybride Mixture-of-Experts (MoE)
Un total de 456 milliards de paramètres (dont 45,9 Md activés par token grâce à l’architecture MoE) accompagne un mécanisme dit de “lightning attention”.
Lightning Attention – lumière sur ce concept
- Le modèle doit “faire attention” à chaque mot/séquence, ça peut devenir long et lourd quand le texte est très long.
- Lightning Attention découpe le texte en blocs, mélange deux méthodes :
- Inter-blocs : calcul rapide linéaire, utilisant des formules simplifiées.
- Intra-blocs : méthode standard mais limitée à un petit bloc à la fois.
- Le résultat ? Le temps de calcul ne croît plus exponentiellement avec la longueur, mais reste quasi-stable, même pour des contextes très longs.
Fenêtre de contexte de 1 million de tokens
Capable de gérer jusqu’à 1 000 000 tokens (environ 750 000 mots) en entrée et 80 000 en sortie, MiniMax‑M1 ouvre les portes à des usages inédits comme l’analyse de gros contrats ou de code source massif.
Innovations techniques
Derrière le modèle IA chinois MiniMax‑M1 se cachent des évolutions ambitieuses, destinées à rendre l’IA plus efficace, plus rapide et économe en ressources. Mais ces prouesses technologiques demandent des infrastructures spécifiques.
- Lightning Attention
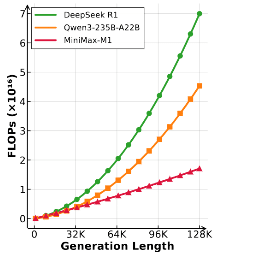
Elle permet une réduction jusqu’à 75 % de FLOPs par rapport à des modèles concurrentiels (DeepSeek‑R1), notamment sur des contextes très longs (~100 000 tokens).
FLOPs – kesako ?
FLOP = Floating Point Operation = opération sur des nombres décimaux. Plus le nombre de FLOPs est élevé, plus le modèle consomme de ressources (temps processeur, énergie, coûts). Par exemple, MiniMax‑M1 utilise seulement 25 % des FLOPs nécessaires à traiter 100 000 tokens par rapport à un modèle comparable comme DeepSeek R1 – ce qui signifie un entraînement plus rapide et moins coûteux.
- Hybrid MoE
Ce design intelligent active uniquement une partie des paramètres par token, maximisant performance et efficacité.
- Entraînement et budget maîtrisé
Au cœur de la formation : CISPO (clipped importance‑sampling), une stratégie d’optimisation RL qui stabilise l’apprentissage de façon plus économique en ressources.
💰 Coût de formation estimé à seulement 534 700 $, contre plusieurs millions pour des modèles concurrents.
CISPO – qu’est-ce que c’est, et pourquoi c’est malin ?
- CISPO signifie Clipped Importance Sampling Policy Optimization.
- C’est un algorithme de Reinforcement Learning (RL), une méthode où le modèle apprend en étant récompensé ou pénalisé, selon ses réponses.
- Contrairement à d’autres techniques qui modifient directement les paramètres du modèle token par token (souvent instables), CISPO limite les écarts dans le calcul du poids d’un échantillon (“importance weight”), ce qui stabilise l’apprentissage.
- Résultat : entraînement plus fiable, plus rapide, et meilleure stabilité, même quand le modèle explore des idées originales (ex. code complexe).
📊 Performances & Benchmarks
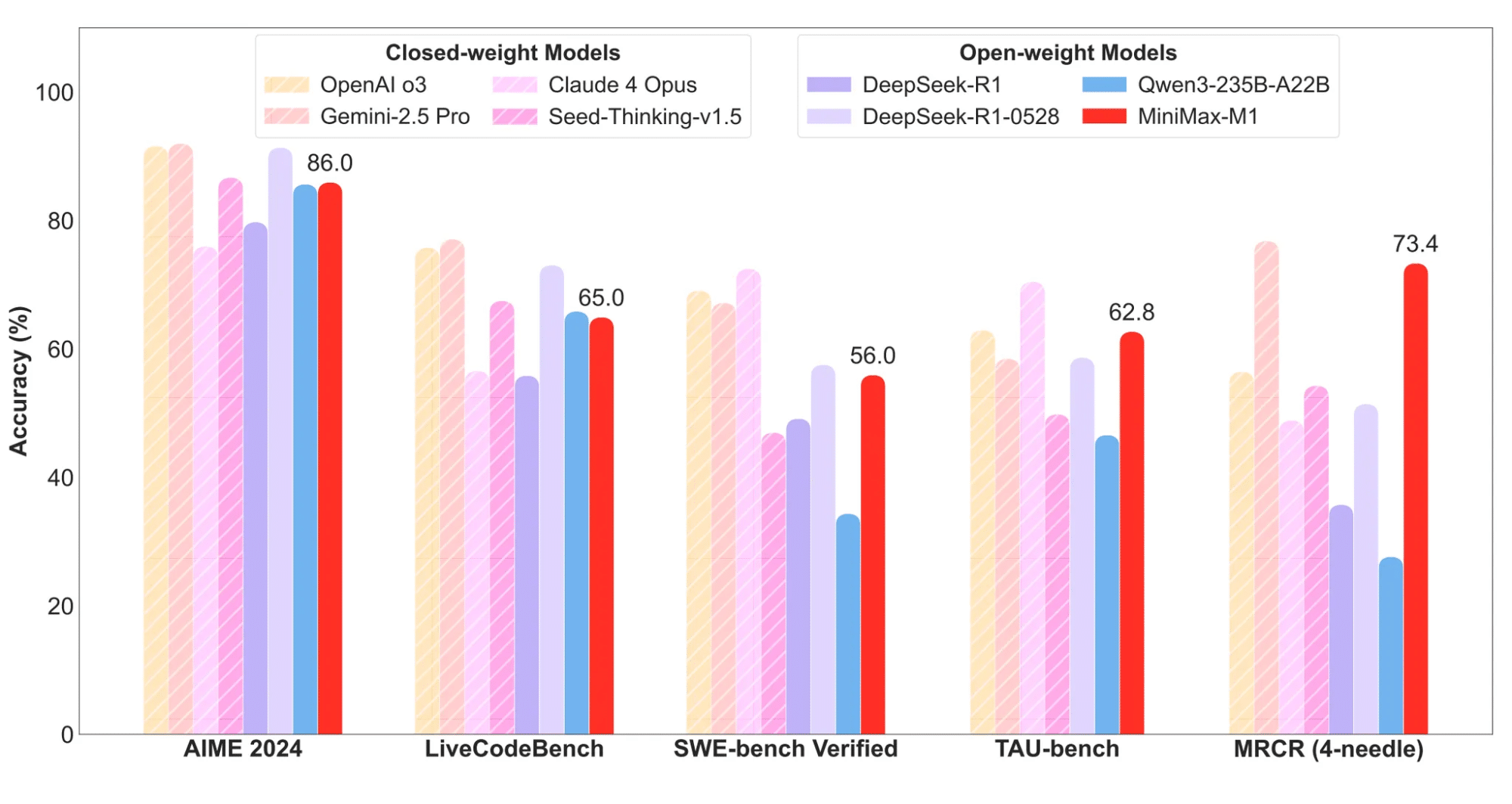
Le modèle IA chinois MiniMax‑M1‑80k (version la plus robuste) se distingue ainsi :
| Tâche / Benchmark | Score MiniMax‑M1‑80k | Comparaison |
|---|---|---|
| AIME 2024 (mathématiques) | 86,0 % (¬GPT‑4o) | devant certains modèles propriétaires |
| LiveCodeBench (codage) | 65,0 % | quasi‑égal à OpenAI o3 (77 %) |
| SWE‑bench (ingénierie SW) | 56,0 % | en tête des modèles open‑source |
| TAU‑bench (usage d’outils) | 62,8 % | devant Qwen3, proche de Claude 4 |
| MRCR (analyse longue) | 73,4 % | très proche des meilleurs |
Ces résultats montrent que M1 rivaliserait avec l’open‑source de pointe, tout en se positionnant comme une solution viable face aux modèles propriétaires. Toutefois, sur certains benchmarks comme MATH‑500 (96–98 %) ou MMLU‑Pro (88–94 %), il reste légèrement en retrait . De plus, les résultats de benchmarks sont toujours à prendre avec un certain recul, par souci d’objectivité.
🗃️ Cas d’usage concrets
Ces performances en font un candidat sérieux pour des cas d’usage complexes : code, analyse de documents, agents autonomes…
Analyse documentaire approfondie
Lecture et résumé de contrats, rapports d’entreprise, thèses, ou volumineuses spécifications métier, sur plusieurs centaines de milliers de mots.
Développement logiciel complexe
Révision de code, debugging, génération de documentation technique, tests, grâce à la capacité de traiter des bases de code étendues en un seul prompt.
Agents et outils automatisés
Création d’assistants capables d’appeler des API, de générer des présentations, d’effectuer des recherches web ou de piloter des workflows complexes (outils fonctionnels intégrés).
- Capacité à interpréter, exécuter du code, générer des présentations ou des posts, grâce à l’API chatbot dotée de fonction‑calling
- Déjà testé pour générer un simulateur animé via code : résultat efficace et conforme
Mathématiques & enseignement
Résolution de problèmes à plusieurs étapes, correction guidée, tutoriels personnalisés.
Grâce à son contexte étendu et sa polyvalence, le modèle IA chinois MiniMax‑M1 offre des applications très intéressantes. À condition de disposer des bonnes ressources techniques.
🧠 MiniMax-M1 : entre prouesse technique et pari stratégique
Et si un modèle open-source chinois venait bousculer la donne mondiale ? Avec MiniMax-M1, on assiste à une double révolution : technologique, grâce à des performances de haut niveau, et stratégique, par une ouverture sans précédent (licence Apache 2.0, API publique, interopérabilité multimodale). Dans un paysage dominé par les géants américains fermés comme OpenAI ou Google, l’IA chinoise MiniMax joue la carte de la démocratisation intelligente, tout en misant sur un écosystème intégré.
L’impact stratégique de MiniMax-M1 résumé
- Démocratisation de LLMs hautes performances : open‑source, licence permissive, contexte très long.
- Concurrence accrue face aux géants privés (OpenAI, Anthropic, Google…) et modèles chinois comme DeepSeek ou Qwen
- Écosystème riche : aligné sur l’offre technologique de MiniMax (Hailuo vidéo, Speech‑02, Talkie…), renforçant synergies multimodales
Promesses tenues, défis à relever
🔥 Ce que MiniMax-M1 maîtrise avec brio
- Grande capacité : contexte jusqu’à 1 M tokens, idéal pour les analyses massives.
- Coût maîtrisé : 25‑30 % de consommation FLOPs par rapport à DeepSeek R1, coût d’entraînement modéré.
- Ouverture totale : licence Apache‑2.0, code sur GitHub et Hugging Face, API publique.
- Flexibilité : deux configurations (40k / 80k tokens) selon les besoins.
- Interopérabilité : support des fonctions API, images, modules multimodaux Hailuo.
🕵️♂️ Ce qui reste à améliorer
- Infrastructure gourmande : haute consommation VRAM, encore réservé aux architectures robustes (GPU H800, H100).
- Coût total supérieur : le coût de développement initial (Text‑01) reste élevé, largement supérieur aux 534 K $ cités en headlines
- Benchmarks réalistes : bien que performants, certains scores restent en retrait des modèles fermés sur le top 1 % des benchmarks.
🧩 Une IA qui fait plus avec moins… et qui voit loin
MiniMax‑M1 représente une avancée majeure dans le paysage des LLM : un modèle ouvert, performant, économe et capable de traiter un million de tokens. Ses innovations (MoE, lightning attention, CISPO) permettent un traitement de documents volumineux, une génération de code avancée et des agents autonomes robustes, à un coût maîtrisé, même si le coût de formation d’abord partagé serait finalement plus un effet d’annonce qu’une vraie promesse… Comme toute technologie de pointe, il nécessite une infrastructure adaptée et doit encore prouver sa supériorité face aux modèles propriétaires sur certaines tâches spécialisées. Toutefois, son rapport performance / coût en fait un candidat sérieux pour les PME, structures R&D, et équipes IA indépendantes.
🚀 Passez en mode “génération intelligente” avec LabSense
Envie d’exploiter le modèle IA chinois MiniMax‑M1 pour booster vos contenus, agents IA, workflows automatisés et analyses volumineuses ?
👉 Découvrez les solutions IA de LabSense : intégration sur-mesure, optimisation SEO intelligente, génération massives multi-formats basées sur open‑data, POI, météo, produits ou clients… en toute sécurité et à moindre coût. Contactez-nous pour un audit et une démonstration dédiée !
💡 Le saviez-vous ?
Les modèles Allready, la plateforme IA de LabSense, utilisent les derniers LLM de pointe et s’inspirent de l’agentivité. Ils peuvent vous aider à booster les performances de votre contenu, qu’il s’agisse d’annonces immobilières, d’articles ou de fiches produits. Les tester, c’est les adopter !








