


Ce qu’il faut savoir en bref 📋
L’essentiel du dossier LabSense sur Mistral 3 en quelques lignes…
👉 TL;DR : Mistral 3 est la nouvelle famille de modèles d’IA de la startup française Mistral AI. Elle se compose de Mistral Large 3 (un modèle Mixture-of-Experts de 675B de paramètres totaux, performant et multimodal) et de Ministral 3 (une série de modèles compacts, jusqu’à 3B de paramètres). L’atout majeur est leur accessibilité : tous les modèles sont open-weight sous licence Apache 2.0 et sont conçus pour fonctionner en local (Edge AI), y compris sur du matériel modeste (4 Go de VRAM). Cette approche réduirait les coûts, assurerait la confidentialité des données et permettrait une personnalisation en profondeur, offrant ainsi une alternative puissante et souveraine aux modèles propriétaires lourds du marché.
C’est dans un contexte ultra dynamique, ponctué de sorties de modèles comme GPT-5 ou Gemini 3 Pro, que Mistral AI, la startup française, a récemment dévoilé sa nouvelle gamme Mistral 3. Celle-ci se caractérise par une double approche : la mise à disposition de modèles de pointe sous licence ouverte (open-weight) et la focalisation sur l’efficience et l’accessibilité des modèles compacts. La famille Mistral 3 propose en effet Mistral Large 3, un modèle MoE conçu pour la haute performance, et Ministral 3, une série de modèles denses optimisés pour l’exécution en local ou sur des appareils à ressources limitées (Edge AI). LabSense présente une analyse complète pour vous aider à identifier les usages possibles pour votre entreprise.
Lancement de Mistral 3 : un peu de contexte…
Dans le paysage bouillonnant de l’intelligence artificielle, la tendance dominante est souvent celle de la course à la taille du modèle. Des modèles toujours plus lourds, nécessitant des infrastructures énergivores et coûteuses. Face à cela, Mistral AI, la pépite française reconnue pour son expertise en R&D, prend un virage stratégique audacieux. L’annonce de la famille Mistral 3 marque un tournant, car l’objectif n’est plus seulement de faire « mieux » que la concurrence (GPT-5.1 ou Gemini 3 Pro), mais de faire « partout ».
En savoir plus

Gemini 3, le nouveau modèle IA de Google, détrône-t-il ChatGPT ?
« Difficile de le rater : depuis hier, un nouveau modèle IA est sur toutes les lèvres, et il s’agit du tant attendu Gemini 3 ! En effet, Google a dévoilé ce qu’il présente comme son modèle le plus intelligent à ce jour… » >> Lire la suite

OpenAI sous tension ? Les leçons du raté de GPT-5 pour l’avenir de l’IA
« La sortie de GPT-5 a été l’un des événements les plus attendus de l’année dans le monde de l’intelligence artificielle. Les promesses d’OpenAI étaient audacieuses, laissant entrevoir un saut quantique… » >> Lire la suite
La nouvelle stratégie de Mistral : l’intelligence distribuée
L’intelligence distribuée se définit comme l’idée que l’intelligence artificielle de pointe n’a pas besoin d’être centralisée uniquement dans d’énormes data centers (le cloud) pour être utile. Au contraire, elle est conçue pour être distribuée et exécutée localement sur une multitude d’appareils, au plus près des données et des utilisateurs. Voici par conséquent quelques implications concrètes de cette notion, telles qu’elles sont mises en œuvre par Mistral :
🗺️ Ubiquité (faire de l’IA « partout »)
L’intelligence distribuée rendrait l’IA universellement accessible.
- De l’Edge au cloud : les modèles Ministral 3 (3B, 8B, 14B) sont si optimisés qu’ils peuvent tourner sur des appareils Edge (en périphérie du réseau), tels que :
- Smartphones et ordinateurs portables (dès 4 Go de VRAM)
- Robots d’usine
- Drones autonomes
- Voitures connectées.
- Fonctionnement hors-ligne : l’IA fonctionne alors sans connexion Internet. Ceci est d’ailleurs essentiel pour les zones non couvertes (secours, agriculture, zones reculées) ou les environnements où la latence est critique (systèmes de pilotage).
Cette accessibilité est renforcée par une distribution très large. Mistral 3 est disponible sur Mistral AI Studio, Amazon Bedrock, Azure Foundry, Hugging Face, Modal, IBM WatsonX, OpenRouter et plus encore.
🔒 Confidentialité et sécurité
Il s’agit ici d’un des arguments les plus puissants pour les entreprises et les particuliers :
- Traitement local des données : si le modèle tourne sur votre appareil (votre PC, le serveur de votre usine, l’infrastructure de votre banque), aucune donnée sensible n’a besoin de quitter l’appareil ou le réseau d’entreprise.
- Souveraineté : pour les entreprises ayant des contraintes légales ou réglementaires (santé, finance, données clients), l’exécution locale assure un contrôle total sur l’emplacement et le traitement des informations.
👛 Efficacité et économie
La distribution de l’IA permet aussi d’optimiser les ressources. On observe ainsi une :
- Réduction de la latence : le calcul étant fait localement, la réponse est quasi instantanée, ce qui est vital pour les applications en temps réel.
- Optimisation des coûts : en utilisant la puissance de calcul déjà présente sur les appareils (le GPU du drone, du PC, etc.), on réduit la dépendance coûteuse au cloud centralisé pour chaque requête.
En résumé, pour Mistral AI, l’intelligence distribuée est la stratégie qui viserait à démocratiser l’IA de pointe en la rendant plus « confidente », moins coûteuse et disponible hors ligne, en s’appuyant sur l’efficacité de ses modèles ouverts.
Mistral 3 : quels sont ses deux nouveaux modèles d’IA ?
La famille Mistral 3 se décline en deux catégories distinctes, chacune répondant à un besoin spécifique : la puissance brute d’un côté, et l’accessibilité de l’autre.
Mistral Large 3, le modèle haute performance pour les besoins avancés
Mistral Large 3 serait le fleuron de cette annonce, positionné comme l’un des meilleurs modèles open-weight au monde.
Une architecture MoE
Tout d’abord, il s’agit du premier modèle Mixture-of-Experts (MoE) de Mistral depuis la série Mixtral. Cette technique d’architecture permet d’activer sélectivement des « experts » (sous-réseaux) en fonction de la requête. Le modèle affiche notamment 41 milliards de paramètres actifs sur un total de 675 milliards. En clair : il serait incroyablement puissant tout en restant plus efficace en calcul qu’un modèle dense de taille comparable.
Découvrez ce qu’est l’architecture MoE

Llama 4 Scout, Maverick et Behemoth : quoi de neuf du côté de l’IA multimodale by Meta ?
« Derrière cette annonce se cache la promesse d’une technologie de pointe dans le domaine de la génération de contenus à grande échelle, notamment texte, image et vidéo, reposant sur une architecture Mixture-of-Experts (MoE)… » >> Lire la suite
Capacités frontières
Entraîné sur 3000 GPU NVIDIA H200, Mistral Large 3 rivaliserait aussi avec les meilleurs modèles propriétaires. Sa fenêtre de contexte de 256k tokens lui permettrait de traiter des quantités massives de données (l’équivalent de plusieurs livres entiers) en une seule requête.
Multimodalité native
Une avancée majeure serait sa capacité à comprendre le texte et l’image nativement. Contrairement à de nombreux concurrents qui « collent » un module de vision, Mistral aurait conçu une IA capable de traiter ces deux types d’informations simultanément.
Des modèles légers optimisés pour le Edge et le local avec Ministral 3
C’est la gamme Ministral 3 qui incarne la vision de l’intelligence distribuée. Conçue pour tourner en local, elle se décline en trois formats : 3B, 8B et 14B paramètres.
- Optimisation record : le tour de force réside dans son optimisation. Ministral 3 peut fonctionner sur un seul GPU avec seulement 4 Go de VRAM (en quantification 4-bit). Il est utilisable entre autres sur des machines modestes, des ordinateurs portables grand public ou des appareils Edge.
- Variantes spécialisées : pour chaque taille, Mistral propose trois déclinaisons sous licence Apache 2.0.
- Base : le modèle pré entraîné
- Instruct : optimisé pour suivre des instructions de chat (comme la génération de contenu)
- Reasoning : variantes dédiées à la logique et à la résolution de problèmes (atteignant par exemple 85% sur AIME ‘25 pour la version 14B).
📊 Quels sont les performances et les coûts de Mistral 3 ?
Les chiffres clés de Mistral 3 et son coût par token ultra-compétitif
Mistral Large 3 a fait ses débuts à la deuxième place des modèles OSS non-reasoning sur le célèbre LMArena leaderboard (et #6 parmi les modèles OSS en général), témoignant de son potentiel niveau d’excellence.
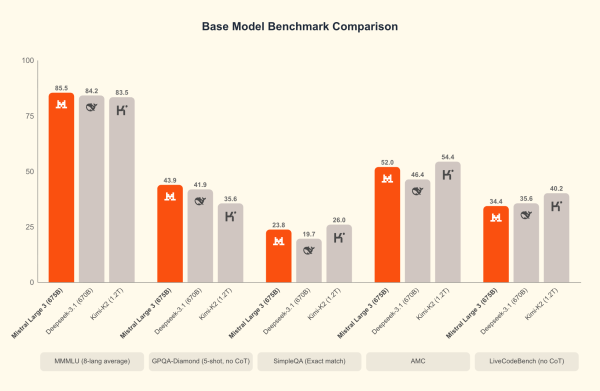
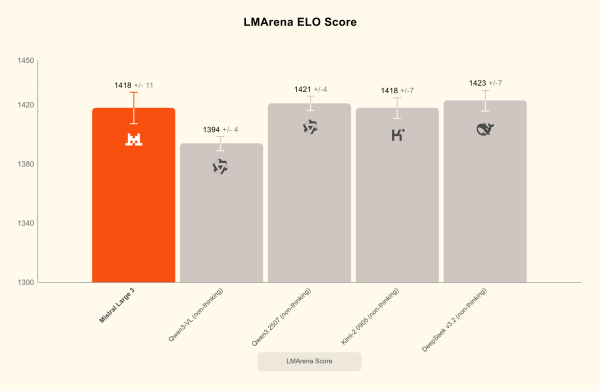
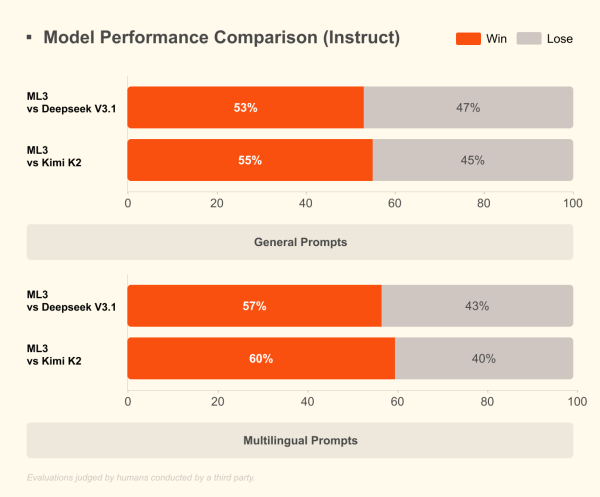
Cependant, l’argument le plus percutant est économique :
| Modèle | Coût estimé (par million de tokens en entrée) |
| Mistral Large 3 | environ 0,5 $ |
| Exemple Compétiteur (GPT-5) | environ 1,25 $ |
Le choix du multilingue, pour aller au-delà des benchmarks américains
Mistral a fait le choix de l’utilisabilité globale. Tandis que la plupart des modèles américains sont majoritairement entraînés sur des données anglophones, l’entreprise aurait augmenté la proportion de données non-anglophones.
« On ne peut pas briller sur les benchmarks populaires et être excellent en multilingue sans faire de compromis. Mistral a choisi son camp : celui de l’utilisabilité globale. » – Guillaume Lample, cofondateur.
Ce choix assure une meilleure pertinence pour les utilisateurs européens et non anglophones. En outre, il entraîne des performances best-in-class sur les conversations multilingues, un atout majeur pour ses utilisateurs internationaux.
L’ouverture stratégique de l’open-weight sous licence Apache 2.0
L’ensemble de la famille Mistral 3 est proposé sous licence Apache 2.0. Ce choix serait fondamental car il marquerait l’engagement de Mistral AI pour l’ouverture. Mistral met à disposition ses poids (d’où open-weight1) et le code sous licence Apache 2.0. Elle offre ainsi le contrôle aux entreprises. C’est l’opposé des modèles propriétaires (closed source), où l’utilisateur est totalement dépendant du fournisseur de l’API. Cette ouverture confère en effet des avantages stratégiques majeurs :
- Confidentialité : en exécutant le modèle sur son infrastructure (en local ou on-premise), aucune donnée ne quitte le réseau de l’entreprise (banques, hôpitaux, données clients sensibles).
- Personnalisation : les modèles open-weight sont plus faciles à fine-tuner (adapter) en profondeur pour des tâches spécifiques ou des datasets propriétaires (ce que LabSense propose via des solutions sur mesure).
- Souveraineté : maîtrise des outils, réduction de la dépendance à un seul acteur technologique, et gestion optimisée des coûts et de la latence.
Limites, concurrence et perspectives d’avenir pour Mistral 3
Des compromis techniques et économiques
Benchmarks américains
Le choix stratégique de privilégier l’excellence multilingue (non-anglais / chinois) oblige Mistral à faire des compromis sur les scores des benchmarks standardisés et majoritairement biaisés vers l’anglais. Exceller partout simultanément reste utopique.
Modèle économique de l’ouverture
Le choix de l’open-weight (licence Apache 2.0) est stratégique pour l’adoption, mais il pose un défi économique. Contrairement aux géants qui monétisent chaque requête API d’un modèle propriétaire (revenus colossaux), Mistral pourrait bientôt se concentrer sur la vente de services haut de gamme. On peut donc imaginer des APIs cloud, du fine-tuning et de la customisation des modèles pour les grandes entreprises. La société doit alors prouver que ce modèle de service apporte suffisamment de revenus face à la concurrence.
Un marché en constante expansion
Le marché de l’IA est saturé par les lancements, ce qui représente à la fois un risque et une opportunité.
Mistral multiplie par exemple les partenariats (HSBC, Stellantis) pour intégrer ses solutions. Pourtant, la société sera attendue au tournant sur la qualité de la délivrance et la rapidité d’intégration, face à des compétiteurs comme Google Gemini ou Claude d’Anthropic, qui séduisent déjà de nombreuses DSI.
De plus, Mistral doit affronter non seulement les mastodontes propriétaires (Gemini, GPT, Claude), mais aussi les autres acteurs de l’open-source très actifs, notamment les laboratoires chinois comme DeepSeek ou Moonshot AI (Kimi K2). Ceux-ci développent également des architectures MoE et des modèles efficaces.
💡 Le saviez-vous ?
Les modèles Allready, la plateforme IA de LabSense, utilisent les derniers LLM de pointe comme Mistral 3 et s’inspirent de l’agentivité. Ils peuvent vous aider à booster les performances de votre contenu, qu’il s’agisse d’annonces immobilières, d’articles ou de fiches produits. Les tester, c’est les adopter !
L’efficacité et l’ouverture, les clés de l’adoption de l’IA en entreprise
L’annonce de la gamme Mistral 3 prouve qu’il est possible de rivaliser avec les modèles propriétaires comme Gemini 3 et GPT en misant sur l’efficacité et l’ouverture plutôt que sur la taille brute. Cependant, ces derniers conservent une longueur d’avance non négligeable. En fournissant des outils performants, multilingues et multimodaux, capables de fonctionner du Edge au cloud à des coûts optimisés, Mistral AI fournit néanmoins une réponse européenne puissante aux enjeux de souveraineté et de rentabilité pour les entreprises. Cette approche d’intelligence distribuée est en passe de devenir la norme, permettant d’intégrer l’IA de manière sécurisée, flexible et SEO-friendly dans tous les processus critiques.
Accélérez vos contenus et processus avec l’expertise IA de LabSense 🚀
Chez LabSense, nous avons produit plus de 400 millions de textes en intégrant les modèles d’IA les plus performants du marché (comme Mistral, GPT et autres). Forts de notre expertise en R&D, nous sommes là pour vous accompagner et vous aider à analyser, corriger et générer en masse vos contenus (articles, textes SEO, fiches produits, etc.) en exploitant l’efficacité de nouveaux modèles.
Contactez l’équipe LabSense dès aujourd’hui pour découvrir comment l’IA peut transformer vos processus et comment nous pouvons vous faire bénéficier de l’avantage compétitif offert par l’ouverture et l’efficience de Mistral 3 !
- Connaissez-vous la différence entre open-source et open-weight ? Open-source : le code est disponible et modifiable. // Open-weight : les poids du modèle (le « cerveau » entraîné) sont mis à disposition. ↩︎






